DB管理者のためのインテリジェント・インフラストラクチャ: SQL Integrated Storage 第2回「可視化」

SQL Serverデータベースのストレージのインサイトを得る
SQL Serverでストレージの問題をトラブルシューティングされた経験があれば、優れた可視化機能がないことはご存知かと思います。このブログは、SQL Integrated Storageに関するシリーズの第2回目で、「可視化」について解説したいと思います。製品全般については第一回で紹介しています。
面倒で非効率的なトラブルシューティングを一変させるSQL Integrated Storage
SQL Serverでは、sys.dm_virtual_io_file_statsを使用して非常に詳細なレベルでファイルの統計情報を追跡します。すばらしい機能ではありますが、表示されるのは、SQL Serverインスタンスを最後に再起動してからの累積統計情報のみです。現時点あるいは2時間前など特定時点の情報の表示ができませんし、SQL Server以外のことについては何もわかりません。
Windowsで提供されるのは、ファイル単位ではなく、ドライブ単位のデータのみです。1つのドライブに1つのファイルしかないのであれば問題ありませんが、通常そのようなことはありません。VMwareなどのハイパーバイザは仮想ディスクレベル(VMwareの場合は.vmdkファイル)でのみレポートです。ストレージシステムの場合は、LUNレベルまたはボリュームレベルになります。
このようにシステムによって、それぞれのデータを簡単に扱えますが、レポートされるレベルや範囲、確認方法がそれぞれ異なっているため、トラブルシューティングを行う際は、DB管理者、ストレージ管理者、仮想化管理者、ネットワーク管理者が協力し、かなり面倒で非効率的な作業を行うことになります。これを一変させるのが、SQL Integrated Storageです。こうした問題に対処し、ストレージスタック全体でデータベースのリアルタイムな状況や履歴の詳細を可視化できます。
ストレージからデータベースを「把握」するインテリジェント・インフラストラクチャ
Tintri VMstoreは、元々仮想マシンレベルでストレージを管理することを目的に開発されており、仮想環境向けのファイル単位のメトリクスを提供するファイルシステムを備えた専用のインテリジェント・インフラストラクチャ・アプライアンスです。Tintriは、このコンセプトをデータベースに拡張して、SQL Serverデータベースのファイルレベルでストレージを管理できるようにしたのです。
各データベースイベントのI/O使用状況をファイルレベルで表示するという、今までに例のない可視化を実現しました。
この仕組みについて、データベースの全体像から始めて、SQL Serverインスタンス単位、データベース単位、そして最終的にはファイル単位で見ていきます。IOPS、スループット、レイテンシの3つの主要メトリクスを始め、あらゆる種類のメトリクスをリアルタイムと履歴の両方のコンテキストで調べます。さらに、読み取りと書き込みの比率、読み取りと書き込みのブロックサイズも確認できます。また、ディスクの使用容量や、圧縮と重複排除の活用状況も確認できるので、推測ではなく実際に、いつ容量が不足するかを把握することができます。調査方法は他にもあります。特に、履歴情報は、使用容量の増加傾向を判断したり、繰り返し発生するパターンを見つけてトラブルシューティングに活かすなど極めて有用です。
主な要因
Tintri Global Center(TGC)を開くと、最初は多くの情報が表示されますが、IOPS、スループット、レイテンシなど、確認したいメトリクスを選択すると、過去1日間の使用状況を示すグラフを確認できます。このグラフの任意の時点をクリックすると、その時点の状況の主な要因を見つけることができます。たとえば図1に示すように、パフォーマンスが突出している時点をクリックすると、その主な要因をすぐに特定できます。また、過去30日間のデータをさまざまな方法で調査することもできます。たとえば、データベースの動作が遅いと言う問い合わせがあった場合に、そのタイムスタンプが4時間前であれば、すべてのデータベースについて4時間前に何が起きていたのかを調べることができます。
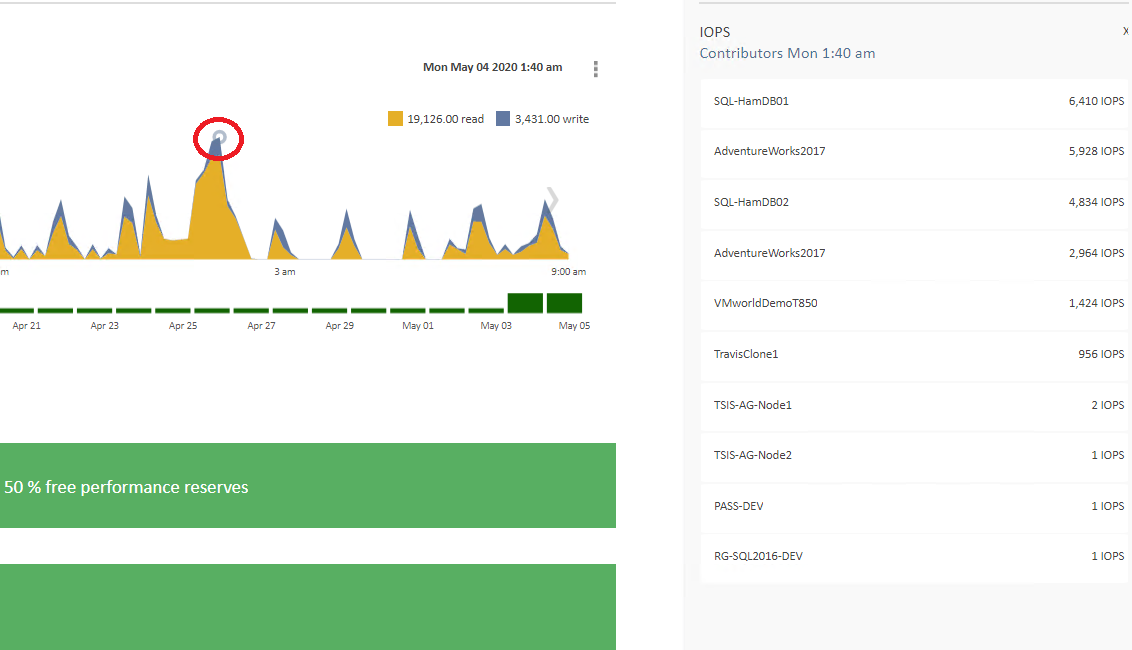
図1:TGCで主な要因を確認
すべてのデータベース
TGCの[Databases]タブをクリックすると、SQL Integrated Storageで管理しているすべてのデータベースが表示されます。どのストレージアレイ上にあるか、あるいはどのSQL Serverに接続されているかに関係なく、すべてのデータベースを確認できます。6つのビューが事前定義されていて、表示できるフィールドは計70以上あります。ほとんどの場合は、これらの定義済みビュー(Database Overview、Performance、Protection、QoS、Space、Troubleshooting)の1つを選択すれば、探しているデータをすばやく見つけることができます。
[Database Overview]ビューには、すべてのデータベースが表示されます。並べ替え機能を使うと、リソースを最も消費しているデータベースやレイテンシの問題が一番多いデータベースをすばやく確認できます。レイテンシをドリルダウンして、その発生元を確認することもできます。図2では、すべてのデータベースをレイテンシの高い順に並べ替えています。複数のSQL Serverが登録され、複数のストレージアプライアンスがあることがわかります。このビューでは、環境内のすべてのSQL Serverデータベースを確認できます。
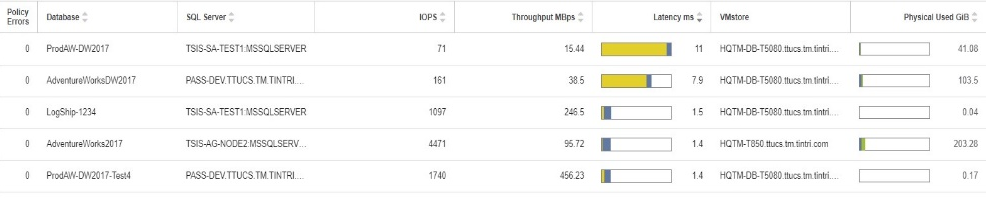
図2:データベースのレイテンシ
レイテンシにカーソルを合わせると(図3)、レイテンシの原因がVMstoreとネットワークのどちらにあるかを確認できます。I/O要求がいつSQL Serverから送信され、いつ受信確認されたかを追跡することができます。これらの数値を追跡する方法について見てみましょう。この図では、0.8ミリ秒がフラッシュ、残りがネットワークになっています。
筆者のラボを例に説明したいと思います。ラボのネットワークは堅牢ではないため、すぐに最大値に達することがあります。レイテンシに関するMicrosoftの現在のベストプラクティスでは、日付ファイル、.mdfファイル、.ndfファイルのレイテンシは10ミリ秒未満、ログファイル(.ldf)のレイテンシは5ミリ秒未満である必要があります。これはSQL Server内で測定されるため、TGCに表示される数値は、WindowsやSQL Serverによって追加されるレイテンシが考慮されていない可能性があります。そのため、十分なヘッドルームを提供するには、これらのベストプラクティスの数値より小さくする必要があります。このレイテンシにより、トランザクション時間が長くなるため、アプリケーションの処理速度が低下します。全体的なレイテンシ/パフォーマンスをリアルタイムで可視化できるようになったことで、レイテンシの数値が基準を満たしていない時間帯を確認できるようになりました。
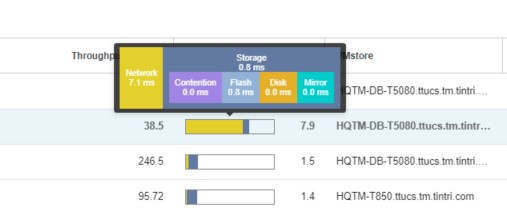
図3:レイテンシの詳細
一般的なインフラストラクチャでは、環境内のすべてのデータベースをストレージの観点から簡単に確認することはできません。一方インテリジェント・インフラストラクチャ、SQL Integrated Storageでは、それが可能になります。ダッシュボードを見るだけで、現在問題が発生しているデータベースを特定したり、使用率が急上昇しているワークロードをすばやく発見したりできます。次は、単一のSQL Serverをドリルダウンして確認してみましょう。
インスタンス単位
特定のSQL Serverのデータベースを確認するには、フィルタを使用して1つのSQL Serverインスタンスのみを表示するか、[SQL Servers]タブで1つのインスタンスを選択します。表示される情報は先ほどと同じですが、1つのインスタンスに絞った情報になっています(図4を参照)。I/Oの多いデータベースをすばやく特定したり、容量順に並べ替えてどのデータベースがどの容量を使用しているかを確認したりできます。表示画面自体は環境全体を通してすべて同じですが、ここではインスタンスレベルで表示されています。
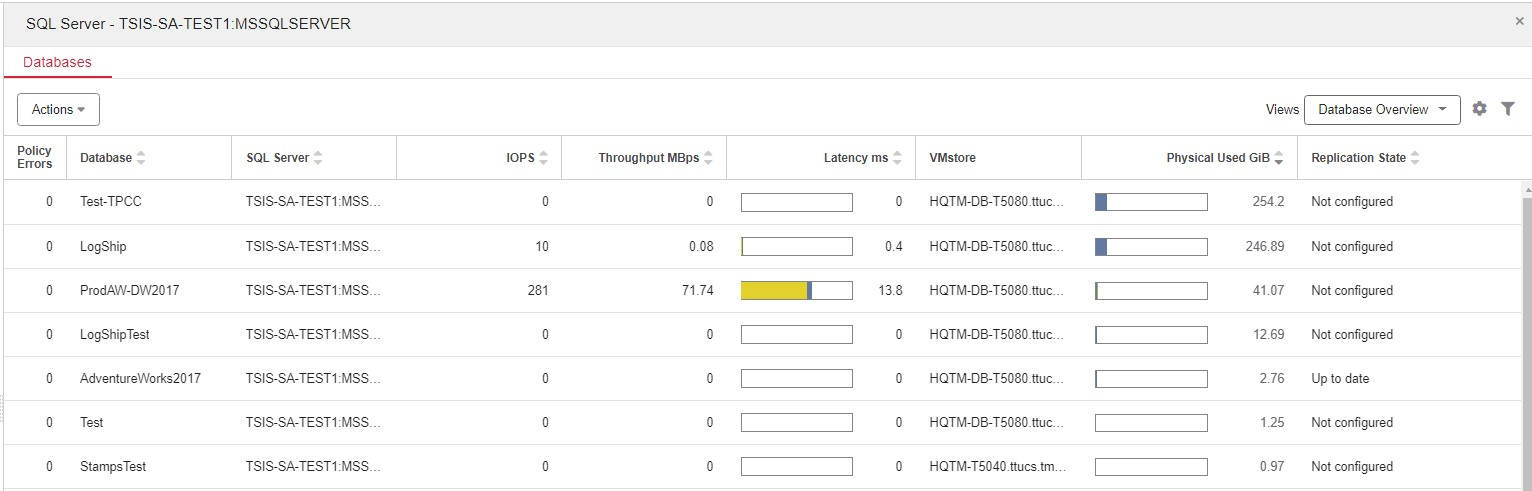
図4:インスタンス単位のビュー
データベース単位
より詳細な情報が必要な場合は、さらにデータベースごとにドリルダウンすることができます。たとえば、この特定のデータベースのIOPS、スループット、レイテンシなど、多くのメトリクスについて、グラフで日付範囲を変更して確認できます。黄色と青色の部分に注目してください。それぞれ読み取りと書き込みを示していて、ここから読み取りと書き込みの動作を確認できます。データベースについて詳細がわかると、さらに特定のワークロードに関連付けることができるようになります。何らかの数値が急増していれば簡単に特定でき、すぐにドリルダウンして詳細を確認できます。
図5には、ProdAW-DW2017というデータベースの情報が表示されています。これは、数日前からのデータを表示して、特定の時点にドリルダウンした画面です。期間にカーソルを合わせると、その特定の期間の実際のデータを確認できます。図5ではスループットとレイテンシのみが表示されていますが、他の多くのメトリクスも利用できます。このように、先月の任意の時点で、各データベースが何を実行していたのかを数秒で確認できます。LUNレポートが特定のワークロードにどのように変換されるのか、sys.dm_virtual_io_file_statsから差分をどのようにロールアウトするのかを理解しようとする必要はありません。インテリジェント・インフラストラクチャを使用すれば、いつでもすぐに情報を入手できます。チームメンバーを集めたら、責任の所在について延々と議論する必要はなく、利用可能なデータを確認して、問題とその解決策の特定に取り組むことができます。
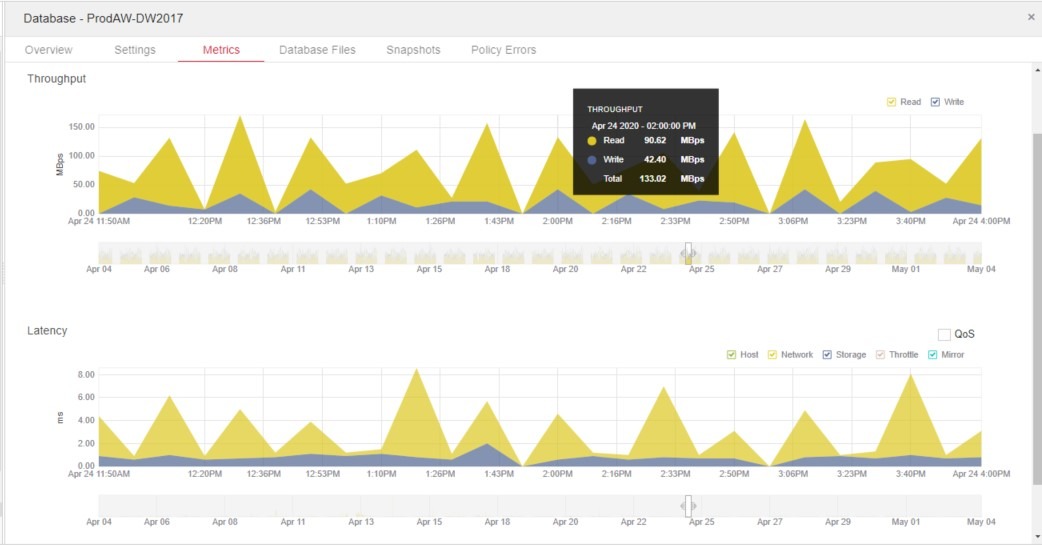
図5:データベース単位の読み取りと書き込みの分析
データベース単位の詳細情報でも不十分な場合は、個々のデータベースファイルごとに、読み取りと書き込み、その他の必要なメトリクスをドリルダウンして表示できます。これは、問題がログやデータファイルに関連しているかどうかを特定するのに役立ちます。
その他のメリット
まだまだご紹介していないメリットが数多くあります。データをすばやくエクスポートすることもできます。すべてのデータベースについて、使用されている実際の容量のレポートを作成し、接続されているストレージの場所とSQL Serverを一覧表示することもできます。情報を細分化して確認する方法は他にも数多くあります。
まとめ
インテリジェント・インフラストラクチャを使用すると、既にあるデータを使用して環境をよりよく把握できます。さらに重要な点として、必要となるプロアクティブなアクションを早い段階で決定して、問題を回避することができます。これらのすべてのデータポイントにより、AIOpsと機械学習を活用して次世代のインテリジェント・インフラストラクチャを実現し、SQL Integrated Storageが現在利用できる機能をさらに向上させることができます。
ストレージパフォーマンスの問題のトラブルシューティングははるかに簡素化されます。インフラストラクチャ担当者とDBAがどちらも同じ画面を見て、問題に関連するデータを確認することができます。リアルタイムまたは過去のデータ傾向を見ることは、毎日のレポート作成と夜間のデータベースメンテナンスの影響を把握するのに役立ち、データベースストレージパフォーマンスへの影響に関してオフクエリを測定することができます。
SQL Integrated Storageでは、さまざまなメトリクスにより、SQL Serverのストレージ使用状況を今までに例のない方法で可視化することができます。全体像を最初に表示して概要を把握し、問題を見つけたらドリルダウンして確認できます。ストレージチームとデータベースチームの間のギャップを埋めることができるツールは常に有用です。TintriはSQL Integrated Storageを提供することで、レベルを引き上げたのではありません。これまでの常識をくつがえしたのです。SQL Serverとストレージとの関係を従来のように捉えるのはやめましょう。各データベースで何が起きているのかを詳細に把握し、データベースレベルでデータベースのストレージを管理する機能を実感してください。生産性の向上をめざし、組織の他の問題も解決できる道が開けたのです。
次回は、データベースのパフォーマンスを取り上げたいと思います。1つの不良クエリが他のデータベースに影響を与えないようにすることを中心に説明する予定です。
本ブログで紹介した内容はwebセミナーにてご紹介していますのでぜひご視聴ください。


